The Self-Paced Reading Task¶
Written by Noah Nelson
Noah Nelson is VP of Product and has volunteered at FindingFive since 2017. He has a PhD in Linguistics from the University of Arizona.
Let’s walk through an example of how a self-paced reading task can be built on FindingFive. We’ll provide sample code throughout that you can customize to build your own reading experiment!
Introduction¶
Self-paced reading (SPR) describes a task wherein participants are presented with tokens of text that they read at their own pace. Researchers measure participants' reaction times to each token to gain insights on how processing times differ across tokens. In general, such reading tasks are especially common in psychology, linguistics, and related research domains.
When the presentation speed of each token is controlled by participants themselves, the task is generally considered “self-paced". Automatic presentation speeds are also found in the literature, especially in studies making use of EEG or other technologies for which predictable timing of stimuli is critical. Tokens in these reading studies can be masked or unmasked and presented in isolation or in sequence. Furthermore, participants can be forced to work progressively through the tokens or allowed to regress to previous tokens (called bidirectional self-paced reading).
In this article, we will walk you through how to build an experiment using a bidirectional self-paced reading (BSPR) task (Paape & Vasishth, 2022) using FindingFive’s convenient Tokenized Text stimulus type. Although this article will demonstrate a bidirectional self-paced presentation of text tokens, FindingFive supports several variations of tokenized stimulus presentations, including not just text, but also image and audio tokens as well.
We will model our demo experiment on one of the conditions in Paape & Vasishth (2022), which makes use of syntactic ambiguity to encourage participants to misinterpret sentences (the so-called “garden path" effect).

A representation of a reader led down the wrong "garden path".
Our demo experiment will also include an acceptability judgement for each sentence. Participants will thus be presented with a sequence of trials, where each trial includes:
-
a single sentence, broken up into roughly phrase-level tokens that participants progress through at their own pace, with the option to regress to previous tokens at any point; and
-
a question following each sentence, asking participants to determine whether the sentence was grammatically acceptable or not.
The Bidirectional Self-Paced Reading Task (BSPR)¶
Let’s begin by setting up our bidirectional self-paced reading task. Our goal is to create garden path sentences that lend themselves to misinterpretation when first read. We will break these sentences up into individual tokens, and allow participants to work forward and backward through those tokens.
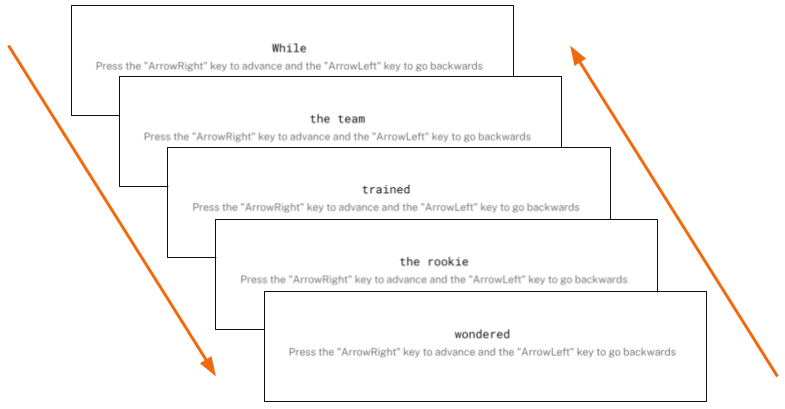
An example bidirectional self-paced tokenized text stimulus at the critical garden path moment.
Creating Stimuli¶
To begin, we will create four sentences including what is sometimes called an NP/Z ambiguity, where a given Noun Phrase can either be interpreted as an object of the main verb, or as the subject of a new clause. Here are the sentences we will use for this, with "|" separating each token:
- While | the team | trained | the rookie | wondered | whether | the rain | would stop.
- Whenever | you | finish | the meal | waits | on | the table.
- Though | the dog | licked | the bowl | was | empty.
- After | the crew | filmed | the actress | stormed off | the set.
To do this, we will create four Tokenized Text stimuli. In our case, we want to present each token alone, with the option for participants to move forward and backward through the tokens in order. Let’s create the first stimulus now. Give it the name “NPZ_1". The definition should look like this:
| A sample tokenized text stimulus (click + for code explanations) | |
|---|---|
- All stimulus code must be encased between two curly brackets
{}(required). - Every stimulus must have a recognized
"type". In this case,"tokenized_text"(required). - Every stimulus must include
"content". In this case, the text to display, broken up into tokens (required). - The
"delimiter"defines the character that FindingFive will use to break up individual tokens (optional, defaults to “ "). - The
"mode"defines how each token should be presented. The"singleton"mode presents each token by itself, one at a time (optional, defaults to “plain"). - Setting
"self_paced"totruegives participants control over when to advance to the next token (optional, defaults tofalse). - Setting
"bidirectional"totrueallows participants to move both forward and backward through the tokens (optional, defaults tofalse). - Setting
"alignment"to “center" ensures that the stimulus is displayed in the center of the screen (optional, defaults to “left").
Now that the first stimulus is created, you can duplicate it to create 3 additional copies. For each newly created copy, change its name to NPZ_2, NPZ_3, and NPZ_4 respectively, and its "content" to one of the sentences given above.
There, we have created our four sentences!
Info
FindingFive also supports batch-uploading stimulus definitions via a CSV file.
Creating Responses¶
When using tokenized stimuli in FindingFive, reaction time data are included automatically for each token. This means we do not need to create any responses to gather that data—nice!
However, reaction time data can only get us so far. Let’s also ask participants for acceptability judgements on the acceptability of each sentence. Why don’t we include a rating scale for acceptability, like this?

An acceptability rating response. Underlying values lie on a 5-point scale with text labels on the first, third, and fifth points on the scale.
To do this, we will create a single Rating response which we can re-use for each sentence. Let’s create this response now. Give it the name “acceptability_rating". The definition should look like this:
| A sample rating response (click + for code explanations) | |
|---|---|
- All response code must be encased between two curly brackets
{}(required). - Every response must have a recognized
"type". In this case,"rating"(required). - Many response types allow you to specify a custom
"instruction"(optional, defaults to“How confident are you in your response?") - Gives custom text labels to each point on the rating scale, each listed one at a time on lines 5–9, encased in brackets
[](optional, defaults to 1–5).
Next, we’ll show you how to put these pieces together to build the complete task!
Creating Trial Templates¶
Trial Templates organize stimuli and responses on a trial and display them to participants. A key concept of trial templates is that each template defines a group of trials of similar structure and function.
For example, in this demo study we can build a single trial template for all four of our sentences. Let’s create this trial template now. Give it the name "NPZ_with_acceptability":
| A sample trial template (click + for code explanations) | |
|---|---|
- Each trial template is defined with its name (user-defined) as the property and its definition as the value, encased between two curly brackets
{}(required). - Every trial template must have a recognized
"type". In this case,"basic"(required). - Trial templates use the
“stimuli"definition to determine how many trials to generate and which stimuli to display on each trial. This format will generate 4 trials with 1 stimulus per trial (optional). - The
“stimulus_pattern"property controls various presentation settings for the trials generated by this template. In this case, setting“order"to“random"ensures a random presentation order of the trials (optional, defaults to“fixed"). - The
"responses"property lists responses to apply to the trials generated by this template. When only one response is given, it is applied to every trial (optional).
That's it! We have defined our trial template for this demo study.
Creating the Procedure¶
The Procedure allows us to organize trial templates into Blocks and define the order in which to show those blocks to participants using the Block Sequence.
In the case of our simple demo study, we only need to define a single block containing our single trial template, and place it in the block sequence. Giving our block the name “BSPR", our procedure should look like this:
| A sample procedure (click + for code explanations) | |
|---|---|
- All procedures in FindingFive currently must be
"type": “blocking"(required). - This
"blocks"property takes a set of curly brackets{}as its value, with each block defined within the brackets (required). - Each block is defined with its name (user-defined) as the property and its definition as the value, encased between two curly brackets
{}(required). - Lists the trial templates which will be used to generate trials for this block. Notice that we included our sole trial template, encased in square brackets
[](required). - All blocking procedures must define a
"block_sequence". In its most basic form, this is a list of blocks to present in order (required).
And that’s it! You just created a simple bidirectional self-paced reading study. Congratulations!
Preview the Experiment¶
You can now preview the experiment by clicking on the “Preview" button above the stimuli section of the study editor. You can then choose to preview the entire experiment, or select individual blocks to preview in isolation. You can even download your own data at the end of the preview. If you notice anything that needs adjusting, make the changes to your study code and preview again—FindingFive gives you unlimited free previews of all your studies!
Conclusion¶
With this base, you can adapt your experiment to include many variations. For example, you may want to change the presentation mode of tokens, or change the task from self-paced to automatically paced. Or, you might want to include other types of garden path sentences, control variants, and instructions for the BSPR and acceptability rating tasks (cf. Paape & Visashth, 2022). Perhaps you even want to use FindingFive’s participant grouping feature to automatically divide participants between control and test conditions. Additionally, it might be wise to include practice trials, and use FindingFive’s conditional branching feature to ensure that participants perform adequately well before advancing to test trials. All of this and more is possible using the FindingFive Study Grammar.
Next Steps¶
Have you finished creating your study? Do you feel stuck on what to do next? FindingFive is here to help!
At FindingFive, we have all kinds of resources at your disposal to help you launch your study, find and pay participants, and collect data. Although FindingFive has its own participant base, we also have integrations with Mechanical Turk, Prolific, and your own institutional pool to help you utilize whatever participant pool fits your needs.
After you’ve collected data, FindingFive compiles it for you into an easy-to-read .csv file that can be opened in R, Python, Excel, Numbers, and more to facilitate easy analysis.